Вступление
Каждый хоть раз делал фотографию. Стоишь где-то, смотришь на город: люди снуют, машины ползут, кто-то сигналит, кто-то паркуется боком. Обычная динамическая каша. Нажимаешь кнопку — и вроде поймал момент.
Но на деле это просто застывший кусок движухи. Фотография — пауза. Город — процесс, который продолжается. Хоть распечатай на холсте, он от этого не станет статичным: он продолжает меняться каждую секунду, пробки растут, кто-то снова перекрыл дорогу, всё как обычно.
С цифровыми системами то же самое. Пока код лежит на диске — идеальный музейный экспонат. Никаких зависимостей, никаких багов, GC спит, сервисы никуда не убегают. Красота, покой и статичность.
Но достаточно запустить программу — и начинается обычная, запрограммированная жизнь. Система просыпается, двигает состояние из одного мешка памяти в другой, цепляет задержки, роняет пару пакетов, подбрасывает tail latency просто потому что может. Всё стандартно, ничего нового.
Не очень строго определим - динамическая система это такая система, у которой:
- есть состояние,
- есть время (пусть даже дискретное - тик-так, инструкции CPU),
- состояние меняется со временем,
- есть правила, по которым оно меняется,
- и всё это происходит, хотите вы того или нет.
Статических систем в реальности не существует, разве что на бумаге. Даже камень - и тот квазистатичен: атомы шевелятся, энергия гуляет. Так что уж за наши хрупкие pipelines точно не каменные монолиты.
Возьмём data pipeline - то с чем я обычно работаю каждый день. Определение простое: цепь, по которой данные проходят путь от «железяки в лесу» до «подготовленного набора, который никто не будет читать, но ругать будут все».
Источник всегда независим, непредсказуем и живёт по своим законам. Можно смело говорить, что данные придут «в среднем за 200 мс», но реальность отвечает: «ха-ха, держи 3 секунды и пакет битых значений сверху».
Чтобы хоть как-то упорядочить хаос, строим архитектуру: складываем всё в data lake (или хотя бы S3), запускаем batch-процессы раз в N минут. На словах красиво. По сути - просто описываем поведение динамической системы: данные есть, данных нет, данные битые, данные неправильные, данные обиделись и ушли.
А вокруг ещё живёт толпа других динамических соседей: операционная система со своим настроением; garbage collector, который просыпается «когда решит»; сеть, которая иногда притворяется, что её нет; кэш, который живёт собственной жизнью; очередь, которая растёт, деградирует и всплывает в метриках в самый удобный момент.
И в конце этого парада - tail latency. Чистый результат накопления микрозадержек, флуктуаций, дрейфа и странностей.
Статика существует в цифровых системах? Смирение, господин разработчик, тут ее нет. Если что санитары за дверью. Система живёт. Даже если вам очень хочется, чтобы она стояла смирно, как фотографии на стене.
Кэш - место, где можно убить много времени
На каждом этапе может пойти что-то не так. Возьмём кэш - наш любимый ускоритель, который должен «хранить результаты повторяющихся вычислений, чтобы всем было хорошо». В идеальном мире кэш ведёт себя спокойно: популярные данные держит под рукой, непопулярные - выбрасывает, экономит память, радует разработчиков и бухгалтеров которые смотрят чеки от AWS.
Звучит как песня. В реальности - как джаз: каждый играет своё, и никто не знает, чем закончится.
Кэш живёт на паттернах доступа. Пять минут назад одни ключи были популярны, ещё через пять - уже другие. Какие-то данные пропали из обращения, и кэш их выкинул. Всё это - динамика, которая происходит в реальном времени, а не в вашей голове.
Теперь пример коммерческого опыта:
У нас есть Celery Worker (часть нашего data pipeline). В качестве очереди - Redis. Celery считает симуляции и научную статистику для 100 человек, которые работают в разное время суток и каждый по своим задачам. Всего примерно 30 разных задач и подзадач - и у каждой свой характер.
Чтобы настроить все эти радости, надо понять простую вещь: кто наши пользователи и как они грузят систему.
Иначе получаем настройку категории «пальцем в небо». Это тот случай, когда после сборки шкафа остаются лишние болтики. Шкаф стоит, но доверия уже меньше.
Дано:
- входные данные в S3 (0.5–100 МБ),
- Celery выполняет вычисления,
- Redis - и очередь, и временное хранилище результатов.
И вот начинается веселье.
Большинство разработчиков (и я когда-то тоже) рассуждают так: «TTL вот такой, maxmemory вот такой, LFU прикручу, LRU оставлю - и поедет». Потом - «подправим по ходу дела». Спойлер: по ходу дела вы чините не Redis. Вы чините собственные нервы.
Настройка кэша без анализа поведения - чистое казино. Казино для вас, для ваших коллег и для самого кэша, который живёт в непрерывном стресс-тесте динамики. Пока вы думаете, что выставили «константы», мир меняет нагрузку, люди меняют паттерны, Celery меняет ритм, GC вдруг решает: «ну ладно, проснусь сейчас», и кэш начинает работать по совершенно другой схеме. Ставки делаете не вы
- ставки делает трафик.
Добро пожаловать в архитектуру как она есть: динамическая, живая, непослушная, но вполне забавная, если перестать ожидать от неё идеальной предсказуемости.
Когда цифры встречают реальность
Допустим, среднее время выполнения задач - 6 секунд, но разброс: от 500 мс до внезапных 26 секунд пару раз в час. (Цифры представленные тут реальные взятые с пылу с жару из Grafana). Есть задача выгрузки файла в S3 - 100 МБ, и UI/UX тут не спасает: иногда загружают что-то, что вообще не подходит под задачу. Бывает. Фокусируемся на системе.
Настройки Redis:
maxmemory: 4gb
maxmemory-policy: allkeys-lru # eviction policy
# Настройки задач Celery
class_1_light:
ttl: 600s
result_size_avg: 3kb
class_2_heavy:
ttl: 3600s
result_size_avg: 200kb
Другие параметры упускаем для упрощения.
Параметры нагрузки:
| Класс задачи | Базовая нагрузка | Средний размер результата | TTL |
|---|---|---|---|
| Класс 1 (Лёгкие) | 50 задач/сек | ~3 КБ | 600 сек |
| Класс 2 (Тяжёлые) | 1 задача/сек | ~200 КБ | 3600 сек |
Вот быстро прикинутая модель кэша. В этой статье без особых объяснений, приймите на веру как говорят в школе.
\[\begin{aligned} \frac{dN_1}{dt} &= \lambda_1 - \frac{N_1}{TTL_1} - \frac{s_1 N_1}{M + \varepsilon_s}\,\alpha\,\max\left(0, M - C\right), \\ \frac{dN_2}{dt} &= \lambda_2 - \frac{N_2}{TTL_2} - \frac{s_2 N_2}{M + \varepsilon_s}\,\alpha\,\max\left(0, M - C\right), \\ M(t) &= s_1 N_1(t) + s_2 N_2(t) \end{aligned}\] \[\begin{aligned} N_1(t),\,N_2(t) &\;\text{— число лёгких и тяжёлых результатов в момент времени } t, \\ \lambda_1,\,\lambda_2 &\;\text{— интенсивности задач (задач/сек)}, \\ \text{TTL}_1,\,\text{TTL}_2 &\;\text{— время жизни результатов (сек)}, \\ s_1,\,s_2 &\;\text{— средний размер результата каждого класса (байт)}, \\ C &\;\text{— лимит памяти под результаты Celery (байт)}, \\ \alpha &\;\text{— коэффициент жёсткости эвикции (сек}^{-1}\text{), обычно }10^7\!-\!10^8, \\ \varepsilon_s &\;\text{— малая константа (}10^3\text{–}10^6\text{ байт) для предотвращения деления на ноль}. \end{aligned}\]Если проанализировать математическую модель и прикинуть числа - выходит примерно 800 МБ (загрузка 20%) в кэше. Всё окей, запас есть, кэш-система устойчива при заданных начальных параметрах системы.
Но любая система должна проектироваться с запасом масштабируемости - на чем я всегда настаиваю, а если масштабируемости нет, то нужно о ней подумать уже сейчас. Лучше заранее покрутить математику - дифуры, нелинейные уравнения, банальные математические прикидки. План устареет в момент написания, но хоть какой-то ориентир появляется.
Теперь беда (для разработчика): нагрузка выросла в четыре раза.
| Класс задачи | Базовая нагрузка | Четырёхкратная нагрузка | Статус |
|---|---|---|---|
| Класс 1 (Лёгкие) | 50 задач/сек | 200 задач/сек | Стабильно |
| Класс 2 (Тяжёлые) | 1 задача/сек | 4 задач/сек | Риск эвикции (75% памяти) |
Пересчитываем модель - получается около 3.09 ГБ, то есть 75% памяти. Чуть увеличиваем число тяжёлых задач - и Redis начинает eviction. Система входит в режим «ищу жертву, кого выкинуть».
И в следствии дальнейшего анализа предел примерно такой:
- 200 задач/сек первого класса,
- 5.3 задач/сек второго - и всё, дальше начинается нестабильность.
Предупреждение о нестабильности: При превышении лимита в \(200\) лёгких задач/сек и \(5.3\) тяжёлых задач/сек (\(\lambda_2 > 5.3\)) кэш переходит в режим thrashing (пробуксовки). Память полностью переполнена, что вызывает лавину постоянных удалений (eviction), при которых Redis тратит больше ресурсов на поиск жертв для удаления, чем на отдачу полезных данных.
Одна-две дополнительные тяжёлые задачи - и кэш превращается в охотника, который бегает по памяти с вопросом: «Кого бы удалить, чтобы оставаться полезным?»
Финал: немного фазовых портретов и много здравого смысла
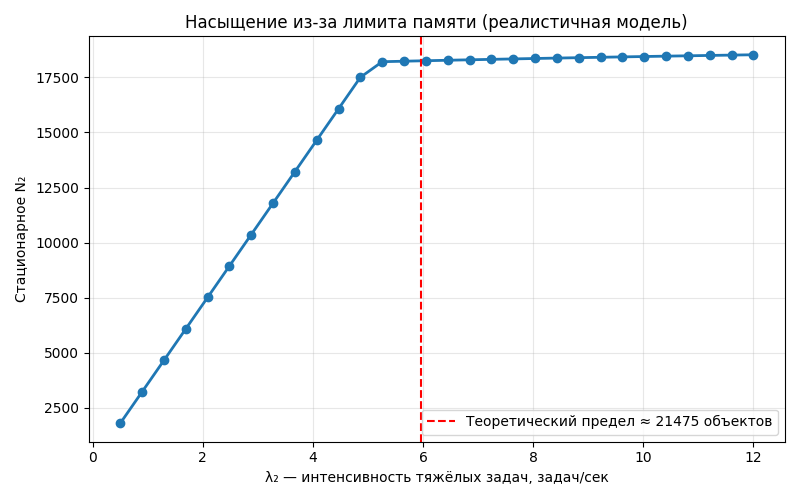
Логично завершить всё это игрушечными графиками из теории динамических систем, которые показывают предел устойчивости. Как меняется конечное стационарное число тяжёлых результатов при увеличении нагрузки:
- При \(\lambda_2 \in \{1,\dots,4\}\) → рост почти линейный.
- При \(\lambda_2 \approx 4,\dots,6\) → система переходит в зону насыщения памяти.
- При \(\lambda_2 > 6\) → Redis входит в режим постоянных эвикций, рост \(N_2\) замедляется почти до нуля → режим thrashing.
Число \(N_2\) отвечает на вопрос: "Сколько тяжёлых результатов будет в среднем лежать в Redis при данной интенсивности тяжёлых задач \(\lambda_2\), когда система уже устоялась?" Ответ: близко к 20–21 тысяче.
Новые параметры (TTL, нагрузка, размер результата, память) начинают проявляться в метриках не сразу, а спустя пару TTL. Это значит после изменения конфигурации нужно ждать несколько TTL, прежде чем оценивать эффект.
Да, ничего общего с точной реальностью. Да, куча оговорок. Но это уже способ хотя бы чуть-чуть приручить цифровой хаос. Системы живут. Они не статичны. Они текут, изменяются, дрейфуют, устают, странно себя ведут, иногда радуют, иногда кусаются. И наша задача - не пытаться заставить их стоять на месте, как фотографии на стене.
Наша задача - понимать, что они динамичны, и учитывать это в каждой архитектурной, инженерной и операционной мелочи.
На этом всё. Дальше - только практика, monitoring и осторожный оптимизм.